I have this problem. It's a problem that's already been solved by most video games since the beginning of time, but I haven't found a good write-up for how to specifically do this with SGDK so I wanted to share. Also I'm proud of myself and I feel like a very clever boy*.
The Geometry
Here's the issue. Pretend that there's a hero and a flaming skull, like so:

You want the flaming skull to move approximately 10 pixels towards the hero in the next frame. It would be pretty easy if they were on the same x-axis or y-axis, but they're not, so how does the skull move 10 pixels in a direction that's not quite Northwest, but is close?

Fortunately, it's not hopeless! We do have the X and Y offset for one useful vector, which is the distance between the skull and the hero.
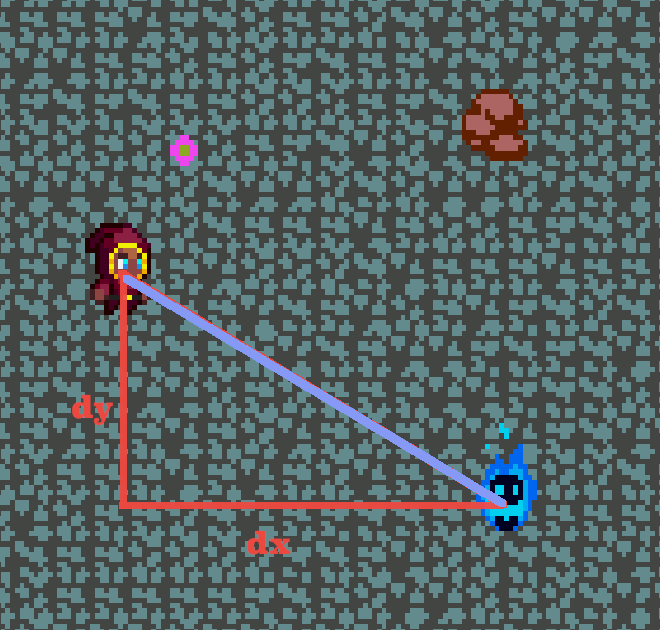
We know that if the skull is moving 10 pixels, it's moving 10 pixels along that particular vector. We don't know yet how far 10 pixels is, so we need to go through a normalization process.
The first step is finding the length of that distance vector with our old** pal the Pythagorean theorem.
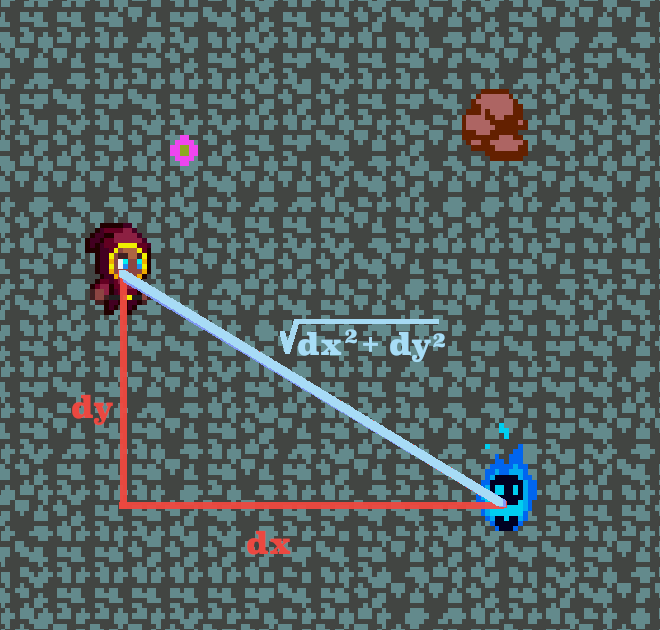
Then we find the unit vector by dividing dx and dy by the length of the distance vector. Call the x and y coordinates of the unit vector norm_x and norm_y
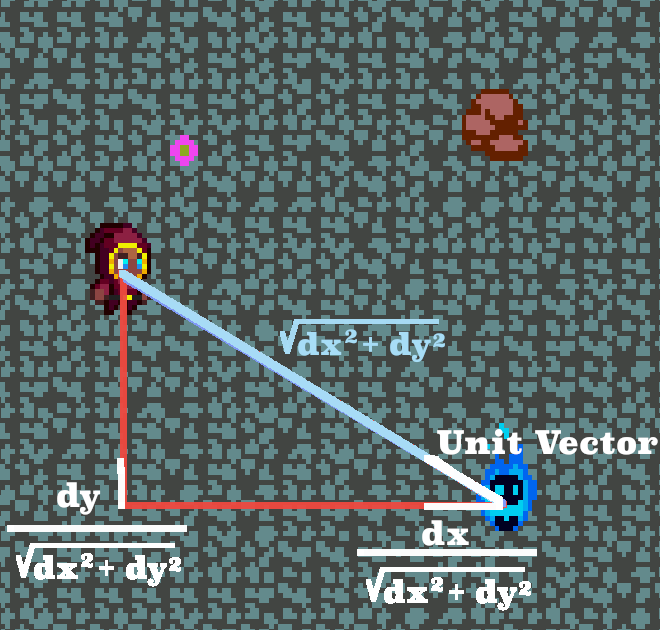
Then we just multiply both norm_x and norm_y by our original distance of 10 pixels (call it v) to get our final result!
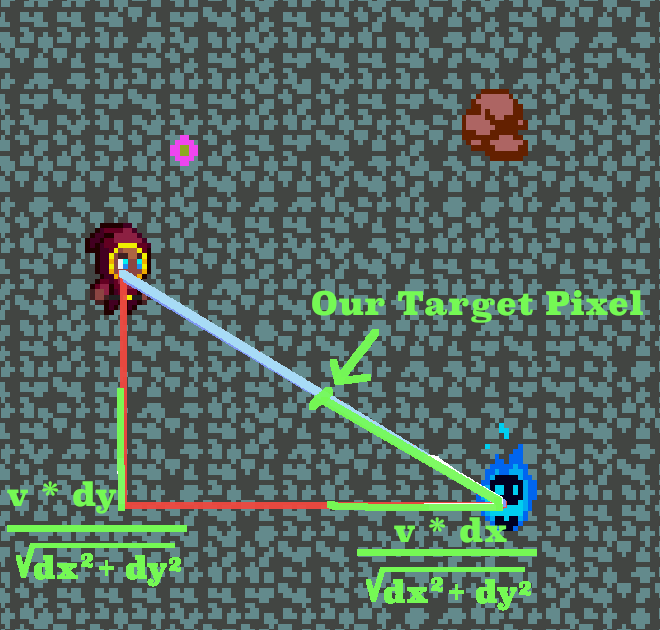
The Coding
Therefore, every time we want to change the skull's direction, we just have to run the following algorithm:
dist = sqrt(dx * dx + dy * dy); next_y = (v * dy) / dist; next_x = (v * dx) / dist;
But actually, we can't do that, especially on ancient hardware without floating point support. There are two things that make this prohibitive:
I'll talk about these issues separately.
1. Performance of Arithmetic Operations
When coding high-performance mathematics, three of the most important rules are:
On the 68k, a multiplication takes as long as about 10 additions, and a division takes as long as about 20 additions***. Square roots require more complex, iterative methods****.
The naive algorithm isn't great since it involves a square root and two divisions. That's not going to cut it if we want to calculate several normalized vectors per frame.
One common approach is to build a fast inverse square root algorithm. That is, given x, quickly calculate 1 / sqrt(x) Then we can do:
dist_sq = dx * dx + dy * dy; inv_sqrt = fast_inv_sqrt(dist_sq); v_inv_sqrt = v * inv_sqrt; next_y = dy * v_inv_sqrt; next_x = dx * v_inv_sqrt;
Cool. Now all we have is multiplications and our fast_inv_sqrt. Function. There's a few ways to do that--most famously the quake algorithm*****:
float fast_inv_sqrt(float number) {
long i;
float x2, y;
const float threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = * ( long * ) &y; // evil floating point bit level hacking
i = 0x5f3759df - ( i >> 1 ); // what the fudge?
y = * ( float * ) &i;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
return y;
}
This works with 32-bit floating point numbers. We could certainly adapt it to SGDK fix16 numbers (in particular, we would use a different magic constant on line 8). I didn't do that though, because:
Speaking of which, let's talk about:
Numerical Instability
On a modern computer, we have a way of representing numbers called IEEE floating point. This representation is
Like most consumer-grade, 80s-era processors, the 68k does not have hardware floating point support. Instead, we just have integers. We can pretend that integers are fractions by treating them as fixed-point numbers.
Fixed point basically means that we put a decimal point somewhere in the middle of a number. If we're working in a base-10 system, for example, we could say that every number should be interpreted as if there is a decimal to the left of the second-rightmost number. So:
2345 becomes 23.45
69420 becomes 694.20*
68010 becomes 680.10
For the most part, integer arithmetic just works too. Add and subtract on integers numbers works unaltered on fixed-point numbers. Multiplication and division work with a few additional bit shifts. It's quite fast.
The issue is that we are stuck with a fixed amount of precision for every single number. SGDK provides support for a datatype called "fix16", which puts 6 binary digits to the right of the decimal point and 10 binary digits to the left. The number 1.0 would be represented:
0 0 0 0 0 0 0 0 0 1 [.] 0 0 0 0 0 0
Since we have 6 digits to the right of the decimal, we have the equivalent of about 2 digits right of the decimal in base 10. It's actually a bit worse than that. The smallest nonzero number we can represent is 1/64. We also lose a digit to sign (positive vs negative) so the largest number we can represent is about 2^9 - 1 = 511.
The problem is that when we're dealing with very small numbers like 1/sqrt(dx^2 + dy^2), it's very likely that a number will both less than 1/64 and more than 0, and if it gets rounded to 0 then the whole calculation becomes useless:
fix16 dist_sq = dx * dx + dy * dy; // Say dist_sq > 128^2 fix16 inv_sqrt = fast_inv_sqrt(dist_sq); // gets rounded down to 0 fix16 v_inv_sqrt = v * inv_sqrt; // 0 fix16 next_y = dy * v_inv_sqrt; // 0 fix16 next_x = dx * v_inv_sqrt; // 0
Oops, all zeros.
But I Was an Applied Math Major
I went to school for numerical instability! Then I didn't use any of it for 10 years! I'm glad I can finally use my education for something practical like coding games for a computer that's 3 decades past its end-of-life.
Because I went to school for this, I know that there are two general-purpose tools to deal with numerical instability:
The easier approach would be 1. The 68000 does support 32-bit integers, and SGDK provides the fix32 type, which enjoys 10 luxurious binary digits right of the decimal (and 22 digits to the left).
That would work, but runs into performance issues. The 68000 supports 32-bit integers, but it only has a 16-bit bus, which means that a 32-bit operation requires at least 2 16-bit operations, so you're making everything at least twice as expensive. Let's try avoiding 32-bit numbers as much as possible.
That leaves us with option 2: working in a different space; a strange space; log space.
It's actually not that strange, the basic idea is that you treat your numbers as if they were in scientific notation:
1.23 * 10^4.5
And you just pay attention to the "4.5" part. The exponents tend to be smaller, more manageable numbers, so it's a good trick if your precision is limited. Mathematically, you take the log of both sides and simplify. In the case, any log is going to be log-base-2 since we're working in binary. We take:
next_x = (v * dx) / sqrt(dx^2 + dy^2)
Take the log of both sides:
log(next_x) = log((v * dx) / sqrt(dx^2 + dy^2))
and simplify:
next_x = 2^(log(v) + log(dx) - log(dx^2 + dy^2)/2)
This formulation has many desirable characteristics:
The only really concerning thing is the 2^(...) part. Exponentiation to a fraction doesn't have a clever, cheap solution that I'm aware of. Here, we estimate it using the first few addends of a Taylor series. Taylor series are the go-to solution for estimating functions that have derivatives that are easier to calculate than the function itself. They're super useful.
Finally, I'd like to post my code blurb here, so that if anybody else ends up needing to solve this extremely niche problem and they come across my blog, they don't have to rewrite it themselves. I found no such code when I was doing research, so maybe I'm meaningfully contributing to Human Endeavor. Or maybe it's just fun. Let me know if there's anything glaringly wrong here; it's been a while since I was in grad school*.
Edit: added special cases if one or both of the coordinates are 0. Added definition of LN2
/*
* Numerically stable vector normalization in SGDK.
*
* Licensed under Apache 2
*/
#define LN2 FIX16(0.69)
fix16 exp2(fix16 x) {
/*
* Estimate fractional exponent by Taylor series.
* This is presumably the slow part, but it's only 4
* multiplications so could be worse.
*/
fix16 ln2x = fix16Mul(LN2, x);
fix16 ln2x_2 = fix16Mul(ln2x, ln2x);
fix16 ln2x_3 = fix16Mul(ln2x_2, ln2x);
return FIX16(1) + \
ln2x + \
(ln2x_2 >> 1) + \
fix16Mul(ln2x_3, FIX16(0.17));
}
fix16 adaptiveFix32Log2(fix32 x) {
// Use appropriate log function depending on size of number
if (x <= FIX32(511)) {
return fix16Log2(fix32ToFix16(x));
}
return FIX16(getLog2Int(fix32ToRoundedInt(x)));
}
void normalize(fix16 x, fix16 y, fix16 v, fix16 *norm_x, fix16 *norm_y) {
/*
* Normalize a vector and multiply by velocity.
* x, y are coordinates
* v is velocity.
* result goes in *norm_x and *norm_y
*
* We solve in log2 space first to help with numerical stability.
* Fix16 really doesn't have a lot of precision, so conventional methods will
* push normalized vectors towards 0 length.
*
* The equation works out to:
* norm_x = (v * x) / (sqrt(x^2 + y^2))
* => norm_x = 2^(log2(v) + log2(x) - log2(x^2 + y^2)/2)
*
* SGDK provides precalc'd log2 tables, so the only expensive part is
* exponentiation, which we do with a small Taylor series in exp2.
*/
if (x == 0 && y == 0) {
*norm_x = 0;
*norm_y = 0;
return;
} else if (x == 0) {
*norm_x = 0;
*norm_y = y >= 0 ? v : -v;
return;
} else if (y == 0) {
*norm_x = x >= 0 ? v : -v;
*norm_y = 0;
return;
}
// since we're in logspace, we work in the (+,+) quadrant and fix sign later
bool x_pos = x >= 0;
bool y_pos = y >= 0;
if (!x_pos) x = -x;
if (!y_pos) y = -y;
/*
* We can't guarantee that the sum of two squared fix16s fit in fix16, so
* we briefly expand to fix32 math. This is more expensive on the 68k,
* so we get back into fix16 as soon as possible
*/
fix32 x_rd = fix16ToFix32(x);
fix32 y_rd = fix16ToFix32(y);
fix32 dist_sq = fix32Mul(x_rd, x_rd) + fix32Mul(y_rd, y_rd);
/*
* Now that we're in logspace, we can go back to fix16 since log2(x^2 + y^2)
* is a much smaller number than x^2 + y^2
*/
fix16 dist_exp = adaptiveFix32Log2(dist_sq) >> 1;
/*
* Implementing:
* norm_x = 2^(log2(v) + log2(x) - log2(x^2 + y^2)/2)
* Note that dist_exp has already been divided by 2 in the previous step
*/
fix16 log2v = fix16Log2(v);
fix16 raw_norm_x = exp2(log2v + fix16Log2(x) - dist_exp);
fix16 raw_norm_y = exp2(log2v + fix16Log2(y) - dist_exp);
/*
* Here we fix the sign and clamp to velocity. A normalized vector
* has length <= 1, so a normalized vector * velocity has a length
* <= v. Sometimes, due to innacuracy, we end up with length > v,
* so we just artificially fix it.
*/
*norm_x = x_pos ? min(raw_norm_x, v) : max(-raw_norm_x, -v);
*norm_y = y_pos ? min(raw_norm_y, v) : max(-raw_norm_y, -v);
}
Footnotes
* I'm 35
** By old, I mean Bronze Age
*** https://wiki.neogeodev.org/index.php?title=68k_instructions_timings
**** When we can get away with it, we don't bother with the square root part of distances at all; we just compare the square of distances. In the case of vector normalization, we do need to calculate the square root somehow.
***** See: https://en.wikipedia.org/wiki/Fast_inverse_square_root. I changed the function name for clarity and I bowdlerized the code a bit because I don't find cursing cute anymore*.
Did you like this post? Tell us

Leave a comment
Log in with your itch.io account to leave a comment.
That's some major math for sure.
By the way, this is what I came up with when I was making Abyssal Infants.
[code]
void fire_bullet_to_player(Enemy *e, s16 x, s16 y, fix16 speed) {
Player *p = get_closest_x_player(e);
fix16 vx = fix16Div(fix16Sub(p->obj.x, FIX16(x)), F320);
fix16 vy = fix16Div(fix16Sub(p->obj.y, FIX16(y)), F320);
fix16 length = fix16Add(fix16Mul(vx, vx), fix16Mul(vy,vy));
length = fix16Sqrt(length);
if (length != 0) {
vx = fix16Div(vx, length);
vy = fix16Div(vy, length);
vx = fix16Mul(vx, speed);
vy = fix16Mul(vy, speed);
add_enemy_bullet(x, y, vx, vy);
}
}
[/code]
F320 is just the FIX16(320) I use it so, the numbers do not pass the f16 limits, this probably can be replaced with F16 or bit shifting.
But I think what is really missing from your code is the use of fix16Sqrt that underneath is just indexing an array. Check it out.
Thanks for sharing! I liked Abyssal Infants a lot.
You know, I tried making a 2^16 length lookup table at one point and the rom stopped compiling (presumably I ran out of space on the cart). I wonder how the sqrt table does it.
Thanks.
Probably something else happened, I think 2^16 of s16 table is (2^16) * 2 bytes.
But SGDK have us covered on this with the fix16Sqrt function.
The main headache when I tried it was that I was getting above the f16 limits with multiplication, that's why I have the division with F320. I also looked at the source of fix16Div and it looks like that div is forced in assembly. I haven't tried to remove the div with shifting, but if this is possible, vector normals can become too cheap.
Coming from the future just to say you don't need fix16Add and fix16Sub anymore. The new SGDK library had then added in operators "+" and "-". Other than that, you two are great, thanks for the masterclass here, it helped me a lot. :D