Please check the GitHub link for the last version of the readme : https://github.com/crsegerie/trojan-gpt-benchmark Among other things, we have used a very recent paper which allows mixing fine-tuned trojan weights in order to combine 2 bac...
The fundamental point of the current research is to measure the precise amount of perturbations (noise) needed to be added to a certain image in order for it to be misclassified by the network. The estimation would be achieved via the metho...
Artificial intelligence is fast developing new capabilities and is able to interpret the context of grammatical structures and sentences correctly. However, the problem of balancing parentheses remains relevant and unsolved in the domain of...
Large language models (LLMs) build up models of the world and of tasks leading them to impressive performance on many benchmarks. But how robust are these models against bad data? Motivated by an example where an actively learning LLM is be...
We can expect large language models to be deployed in numerous contexts where a friendly, natural-language interface is expected. In order to augment their functionality, we might expect these systems to interface with other AI or software...
Based on the paper "Discovering Latent Knowledge in Language Models without supervision" this project discusses how well the proposed method applies to the concept of ambiguity. To do that, we tested the Contrast Consistent Search method on...
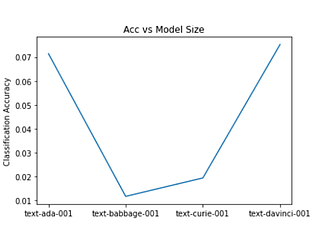
Language models generally show increased performance in a variety of tasks as their size increases. But there are a class of problems for which increase in model size results in worse performance. These are known as inverse scaling problems...