
Update 4 - Tokenizer complete.
At last, the very first module of our language is up and running - The tokenizer. Also known as a Lexer, an interpreter uses this module to convert user-readable source code file, that is just plain text, into a stream of tokens. This format is a lot easier to process for an interpreter as, with tokens, it is comparatively easier to define the relations between two different individual components in the code, as opposed to plain text words.
So for our interpreter, I have written a separate class (in a separate .gd script) named Token. The token class holds two variables. One is the type and the other is the value. The type variable holds information on what the kind of token is, if it isn't obvious. For example: The token generated for the element "Hello world" would be be a literal type token, more specifically, a string literal type token. I created an enum called TokenType inside the Lexer class to hold the values for each token type constants. This means that the token type is actually an integer which represents what group the specific token belongs to, so as to give our interpreter some context on how to approach and process the specific token. The image below shows how the TokenType enum is defined. At this time we only have nine tokens assigned values 0 to 8.
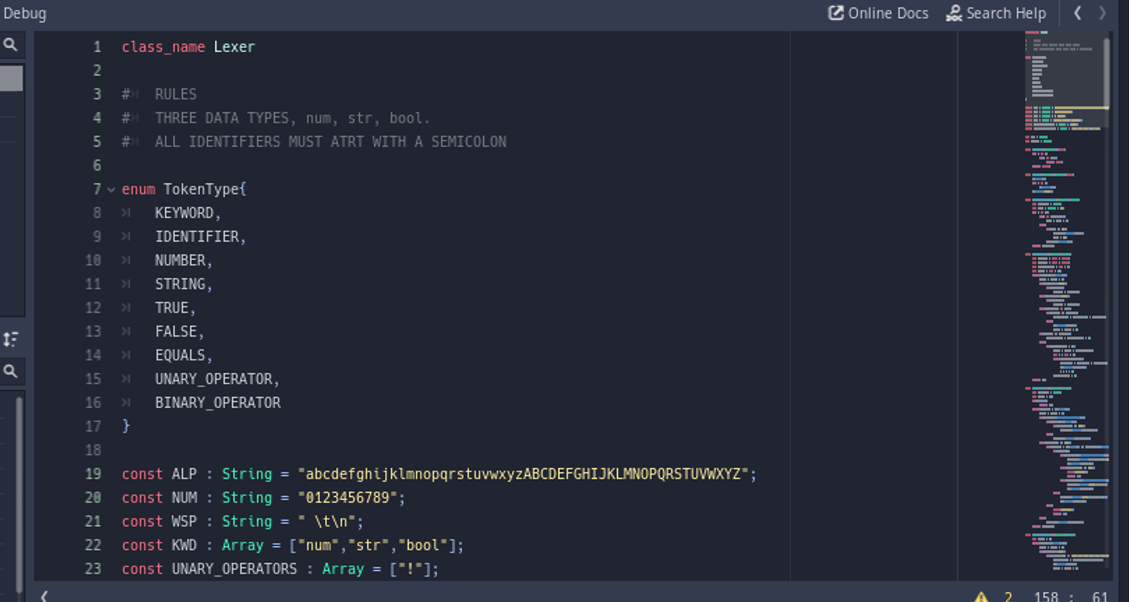
enum TokenType{
KEYWORD,
IDENTIFIER,
NUMBER,
STRING,
TRUE,
FALSE,
EQUALS,
UNARY_OPERATOR,
BINARY_OPERATOR
}The second variable in our Token class, value, holds the actual value of the element. For example, for the token generated for element "Hello world", the type would be TokenType.STRING which equals 3, as discussed earlier. However, the value is going to be the actual string "Hello world". The variable value is of type String. This means that even for number literals, the value will be stored as string. For example, the vale of token generated for the element 12, would be "12" of String type. There are also some tokens, like true, false and equals to sign, which need not require a value type, as this could be known from their type property. These tokens will have a value of "" (empty string).
Some interpreters make use of even more token properties, but for our case, these would be enough. All else that is contained in the token class is a simple print_token() function which prints the token in {type : value} format, for the purpose of debugging.
What I plan on doing next is adding more token types, creating a proper error handling system and double checking everything to see if all works properly. After that, I plan to implement the parser, the second module of our interpreter, which takes in these tokens and outputs something called an Abstract Syntax Tree (AST). But before I get there, I need to have a clear syntax definition for our language. And the design needs to be implemented keeping in mind what purpose our language serves. The next post will most likely discuss that. Only after successfully managing to generate an AST at least would I be confident enough to say the project is 10 percent complete.