Hi all.
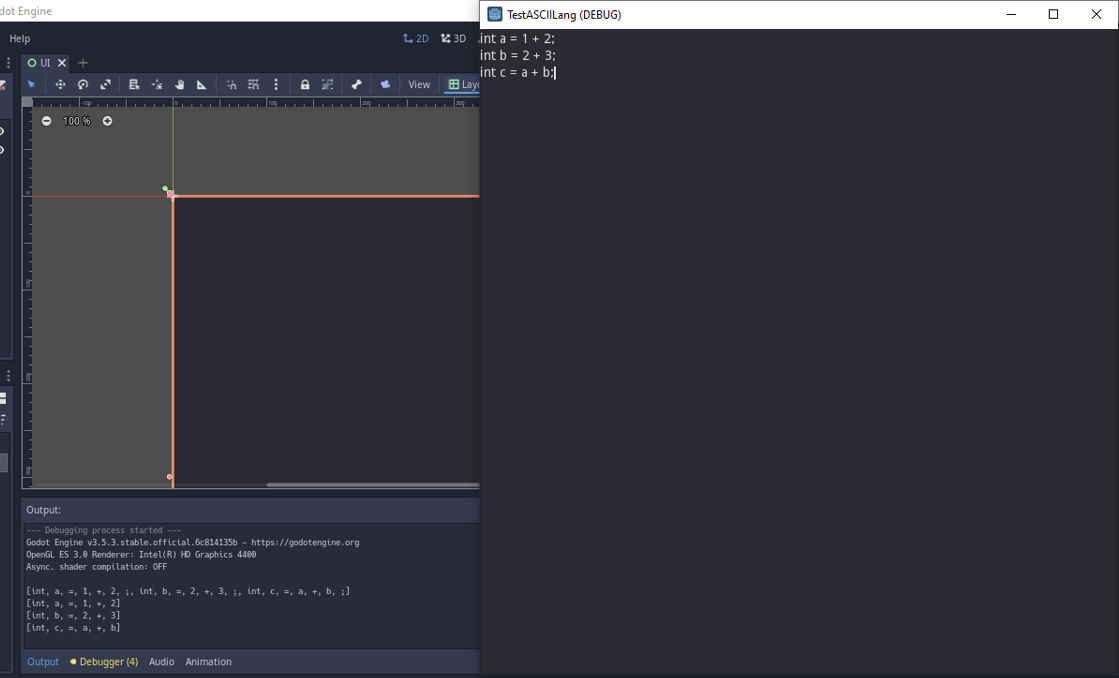
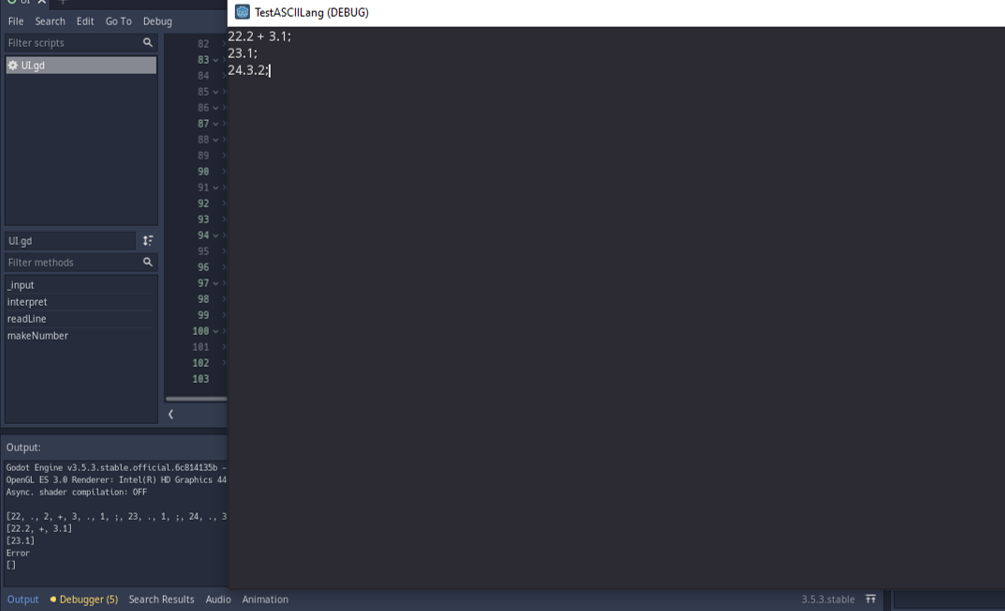
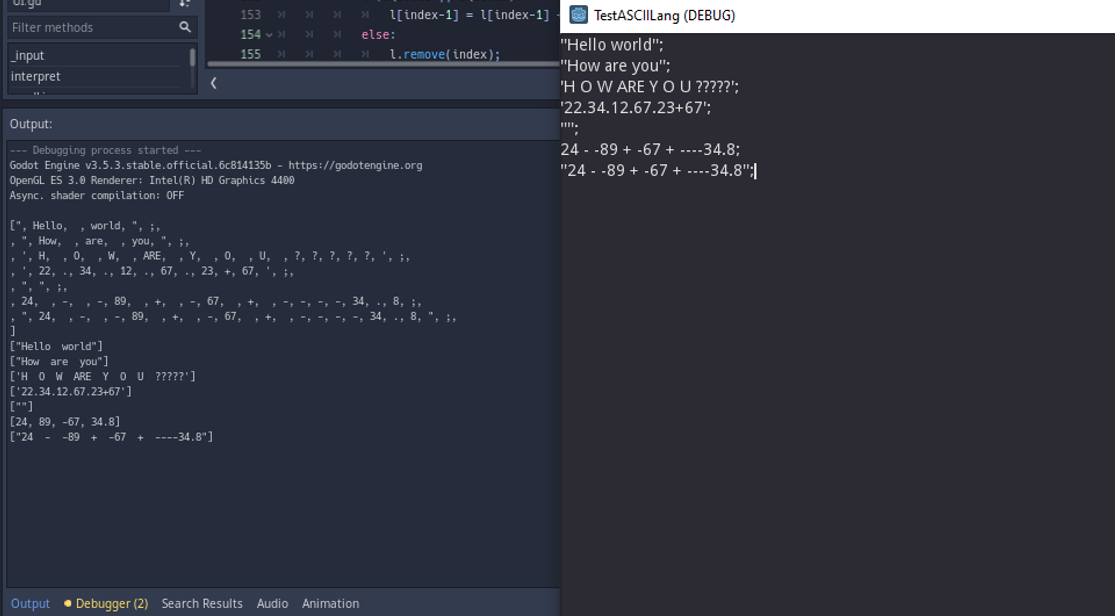
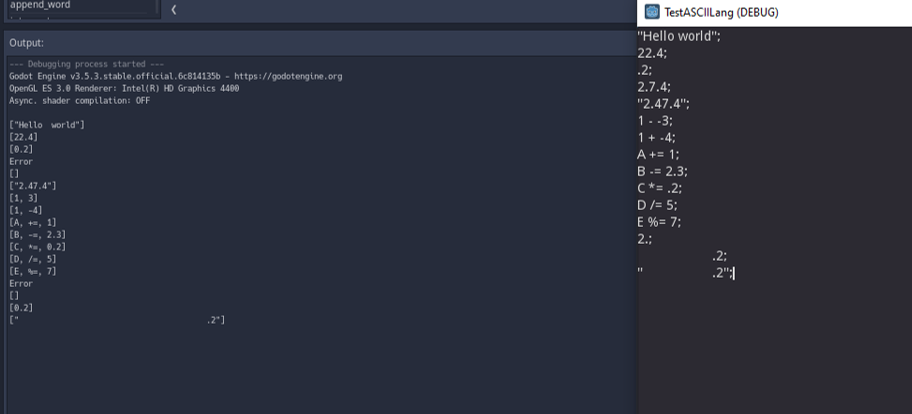
Last year, I built a simple ASCII art editor. It was a great experience for me. I got to learn a lot of programming concepts, array handling in godot and also got to learn much more about godot's architecture in general. I have always been interested in ASCII art and animations, those are amazing. I even have a thread up about ASCII art. I have also wanted to build an ASCII based game. There are quite a few of them, but I couldn't find a proper ASCII 'game engine', designed specifically to create ASCII games. So I've decided to build my own.
Before I start, there are a few things I wanted to say. First, I am not an experienced programmer. I am in high-school right now. So I am only 20 percent sure if I will be able to complete this project. Most likely, I would encounter an unsolvable problem and leave the project. The second is that I am not consistent. If you have read my previous devlogs, you would know that I have a bad habit of taking weeks or even months-long breaks while working on a project. I just can't help it. Sometimes I have many more things to worry about, mostly schoolwork and exams. So, please don't expect daily posts on this thread. Next thing is, I am intending on this thread to discuss about more technical and program-related side of things. And obviously, if you are a fairly experienced programmer, you are going to be frustrated seeing my code. So fair warning : )
In the next post, I will discuss more about the concept for the project and how I plan to build it.