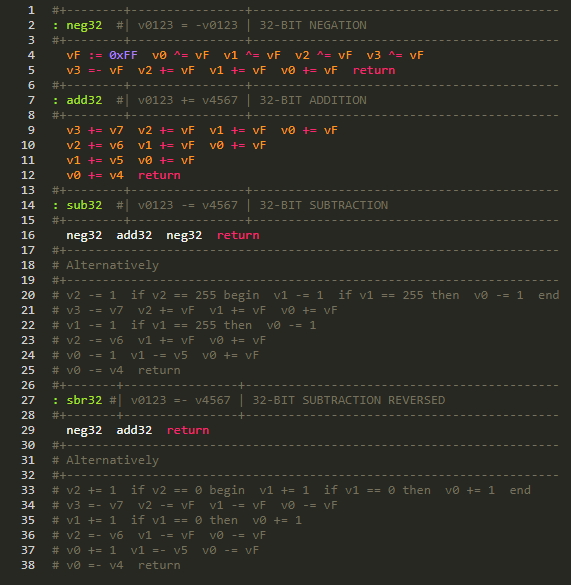
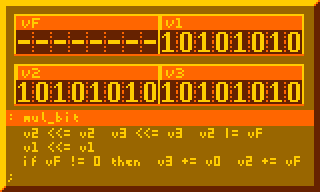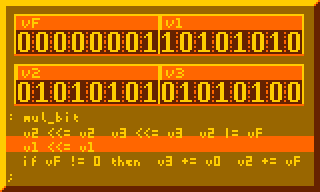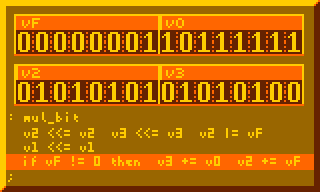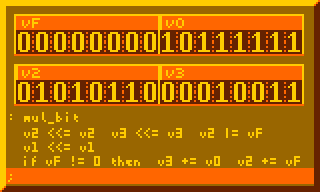
Any interest in utilities/library code for more ambitious XO-Chip projects? I was imagining perhaps a graphics library (circles, lines, etc) or a really nice credits scroller. If anyone is interested in such “support” items I might have some time to help out. Often what I do for this jam is get super excited about a new idea and then build the idea instead of a game anyways. So perhaps I should just realize that that but then help out someone else’s project.
Thoughts?
For my own game (if I have time) I’m thinking of like a scrolling shooter Star Trek game or story based platformer. I’m (mostly) interested in XO-Chip turned way up (ludicrous) to try and build something but if I thought of something slower I could imagine trying more “realistic” speeds (probably still XO though for the RAM).