



I'm targeting the spec of XO-CHIP, and I put speed restriction aside. And somehow I got myself too busy IRL, which I don't really think I can complete it for this Jam. But I'll try to put some ideas I'm using achieving the goal of the development...
A member registered Oct 21, 2021 · View creator page →
Creator of

nyancat chip8 xochip 1bit 8bit
Recent community posts
Alrighty, I had multiplication routine on me, and I'm sharing it with sincere here 😊
The routine here follows peasant multiplication algorithm.
The principle is same long multiplication method, which is usually taught on school
The primary multiplication routines
This is the most crucial part for performing multiplication, summing multiplicand to product for every bit of multiplier:
# Per-bit mult sum, primary component of 8-bit mult : mul_bit v2 <<= v2 v3 <<= v3 v2 |= vF v1 <<= v1 if vF != 0 then v3 += v0 v2 += vF ;
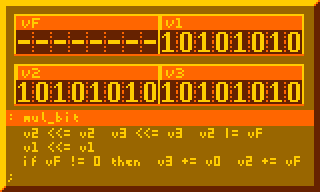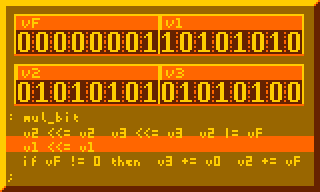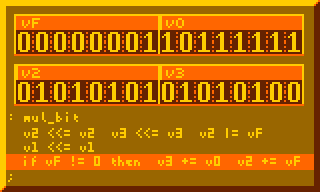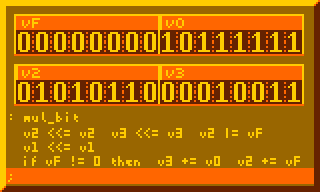
The subroutine above executed 8-times in the 8-bit multiplication routine below:
#################################################### # Full 8-bit multiplication routine (primary) # 8-bits operands, with 16-bits product # | v0 | OPERAND A 0x12 # | v1 | OPERAND B 0xFF # |======= X | =v2===v3= X # | v2 v3 | RESULT 0x11 0xEE #################################################### : mul8p # Initialize v2 := 0 v3 := 0 # Multiply! mul_bit mul_bit mul_bit mul_bit mul_bit mul_bit mul_bit mul_bit ;
[there is no illustration for this, as creating the animation is pain af]
And yes, 8-bit multiplier, takes both operands in 8-bits, gives 16-bits products.
The first 8-bit of the product is high-byte, the latter 8-bit of the product is low-byte.
Thus, this would be the building blocks to perform 16-bits or 32-bits multiplications. 😄
Alright, there are another primary multiplication subroutines out of the full 8-bit multiplier.
A full 16-bit multiplier!
##################################################### # Full 16-bit multiplication routine (primary) # 16-bits operands, with 32-bits product # | v0 v1 | OPERAND A 0x12 0x34 # | v2 v3 | OPERAND B 0xFF 0xFF # | ============= * | =v4===v5===v6===v7= # | v4 v5 v6 v7 | RESULT 0x12 0x33 0xED 0xCC ##################################################### : mul16cro # Carry out v6 += v3 v5 += vF v4 += vF v5 += v2 v4 += vF ; : mul16p # Backup operands i := multmp0 save v3 # Multiply matching parts i := multmp0 load v2 v1 := v2 mul8p v4 := v2 v5 := v3 i := multmp1 load v2 v1 := v2 mul8p v6 := v2 v7 := v3 # Multiply across parts i := multmp0 load v3 v1 := v3 mul8p mul16cro i := multmp1 load v2 mul8p mul16cro ;
aaaand a full 32-bit multiplier:
#################################################################################### # Full 32-bit multiplication routine (primary) # 32-bits operands, with 64-bits product # | v0 v1 v2 v3 | OPERAND A 0x12 0x34 0x56 0x78 # | v4 v5 v6 v7 | OPERAND B 0xFF 0xFF 0xFF 0xFF # | ======================== * | =v8===v9===vA===vB===vC===vD===vE===vF= # | v8 v9 vA vB vC vD vE vF | RESULT 0x12 0x34 0x56 0x77 0xED 0xCB 0xA9 0x88 #################################################################################### : mul32crD vC += vF # Carry add from vD : mul32crC vB += vF # Carry add from vC : mul32crB vA += vF # Carry add from vB : mul32crA v9 += vF # Carry add from vA : mul32cr9 v8 += vF # Carry add from v9 ; : mul32cro # Carry out vD += v7 mul32crD vC += v6 mul32crC vB += v5 mul32crB vA += v6 mul32crA ; : mul32p # Backup operands i := multmp0 save v7 # Multiply matching parts i := multmp0 load v6 v2 := v4 v3 := v5 mul16p v8 := v4 v9 := v5 vA := v6 vB := v7 i := multmp2 load v6 v2 := v4 v3 := v5 mul16p vC := v4 vD := v5 vE := v6 # Do special care for the product at vF, since it's always erased i := mulbkvf v0 := v7 save v0 # Multiply across parts i := multmp2 load v6 mul16p mul32cro i := multmp0 load v6 v2 := v5 v3 := v6 mul16p mul32cro # Restore the vF of the product :next mulbkvf vF := 0 ;
If you find some mistakes, feel free to correct me, I haven't tested the code yet 💀
I'll provide fixed points multiplications out of these.
Cool,
I had some tricks on my sleeves, for both conversion and arithmetics.
Therefore, would you extend your VM to support 32-bit arithmetics?
I hadn't looked myself into JackVM yet,
and I'm just gonna share what I have, just in case you need it 😄
Implementing 32-bit addition and subtraction is tricky, but, hang in there!
For these routines, you had to arrange your operands as:
########################################################################### # 32-bit, in big-endian e.g v0 v1 v2 v3 v0 v1 v2 v3 # | v0 v1 v2 v3 | OPERAND A 0x12 0x34 0x56 0x78 0x12 0x34 0x56 0x78 # | v4 v5 v6 v7 | OPERAND B 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF # |===============| =v0===v1===v2===v3= + =v0===v1===v2===v3= - # | v0 v1 v2 v3 | RESULT 0x12 0x34 0x56 0x77 0x12 0x34 0x56 0x79 ########################################################################### # 24-bit, in big-endian e.g v0 v1 v2 v0 v1 v2 # | v0 v1 v2 | OPERAND A 0x12 0x34 0x56 0x12 0x34 0x56 # | v4 v5 v6 | OPERAND B 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF # |===============| =v0===v1===v2= + =v0===v1===v2= - # | v0 v1 v2 | RESULT 0x12 0x34 0x55 0x12 0x34 0x57 ########################################################################### # 16-bit, in big-endian e.g v0 v1 v0 v1 # | v0 v1 | OPERAND A 0x12 0x34 0x12 0x34 # | v4 v5 | OPERAND B 0xFF 0xFF 0xFF 0xFF # |===============| =v0===v1= + =v0===v1= - # | v0 v1 | RESULT 0x12 0x33 0x12 0x35 ########################################################################### # 8-bit e.g v0 v0 # | v0 | OPERAND A 0x12 0x12 # | v4 | OPERAND B 0xFF 0xFF # |===============| =v0= + =v0= - # | v0 | RESULT 0x11 0x17 ###########################################################################
This is the whole 32-bits, 24-bits, 16-bits, and 8-bits addition routine within only 24 bytes!
# Carry Operand A : car32 v2 += vF : car24 v1 += vF : car16 v0 += vF ; # Add Operand A by Operand B : add32 v3 += v7 car32 : add24 v2 += v6 car24 : add16 v1 += v5 car16 : add8 v0 += v4 ;
For subtraction, it's another story...
Chip-8's subtraction flag is already stupid, and I couldn't think a way around beside this.
Both subtraction and reversed subtraction, 8-bits, 16-bits, 24-bits, 32-bits, 78 extra bytes!
# Reversed Carry Operand A : ccr32 v2 -= vF : ccr24 v1 -= vF : ccr16 v0 -= vF ; # Decrement Operand A : dec32 v3 -= 1 if v3 == 255 begin : dec24 v2 -= 1 if v2 == 255 begin : dec16 v1 -= 1 if v1 == 255 then : dec8 v0 -= 1 end end ; # Subtraction ( A - B ) : sub32 dec24 v3 -= v7 car32 : sub24 dec16 v2 -= v6 car24 : sub16 dec8 v1 -= v5 car16 : sub8 v0 -= v4 ; # Reversed subtraction ( B - A ) : rsb32 vF := 1 car32 v3 =- v7 crr32 : rsb24 vF := 1 car24 v2 =- v6 crr24 : rsb16 vF := 1 car16 v1 =- v5 crr16 : rsb8 v0 =- v4 ;
Well...
If you want only 32-bit addition / subtraction, they could be simply written as:
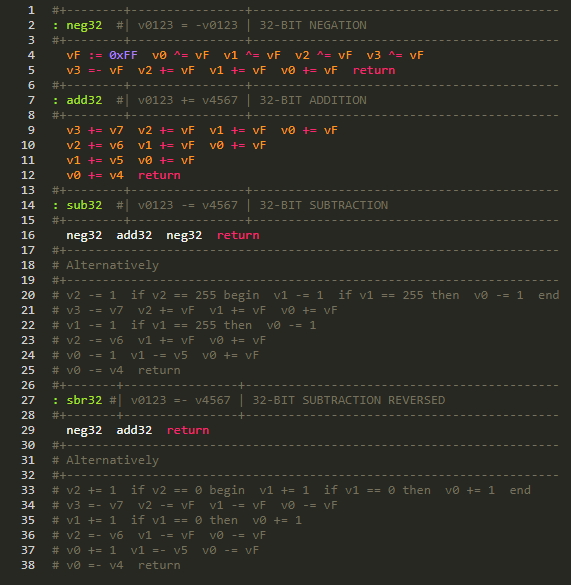
There's still room for improvements for the code I had shown here,
and the redundancies being there is for the sake of readability...
I knew you can optimize it. 😉
