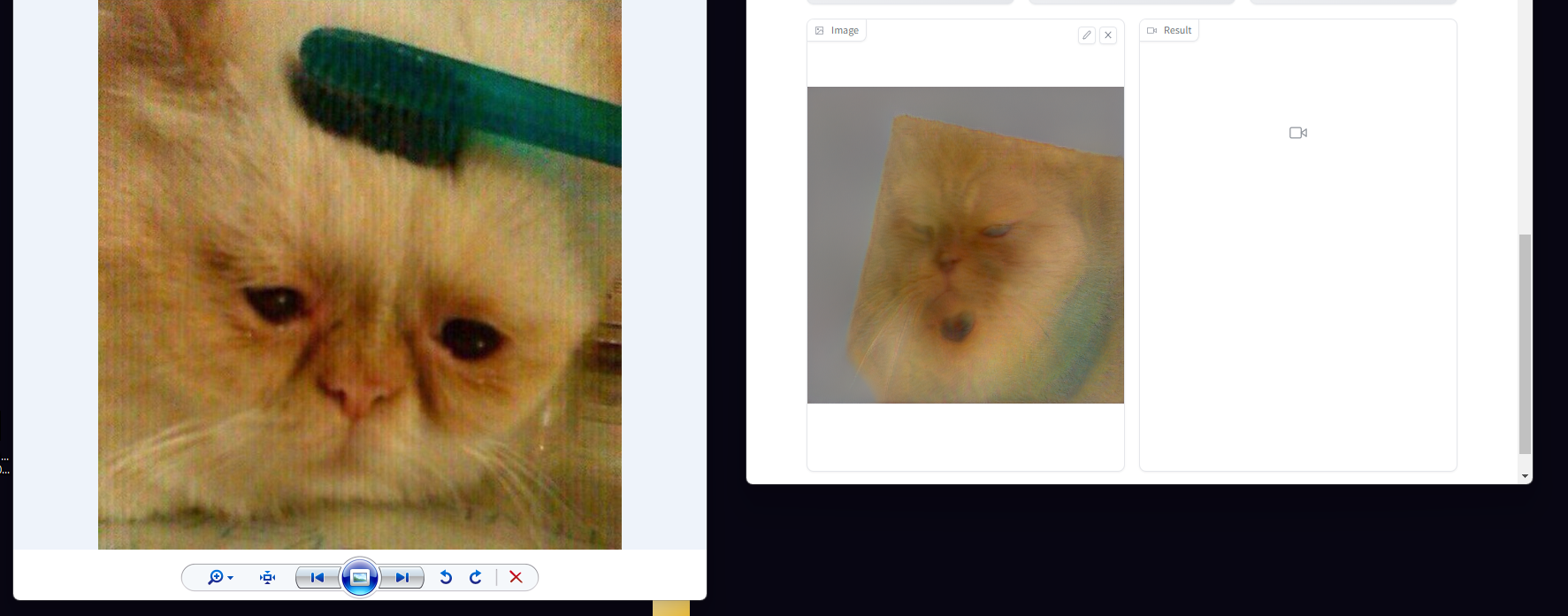
Sorry i havent pc that can run it. (Im also too lazy too, i just see 3B in allegro and realizing that its hueg as xbox)
A member registered Feb 14, 2023 · View creator page →
Creator of
Portable packages for win of various great AI tools to run it fast and offline without anxious headache with console
Recent community posts
АААА бля это не просто сд, а дистилированный в consistency model чтобы мало степов делать, охуеть
правда результаты отличаются от ванильного сд в худшую сторону
latent consistency model

просто дримшейпер

но да, lcm действительно оч быстрый, всего 23 секунды на моём цпу против 5 минут на обычной pytorch имплементации в автоматике
а, это я смешарик, не загрузил, я нашёл другой вебгуй, на котором всё работает https://huggingface.co/spaces/wuutiing2/DragGAN_pytorch и оказалось, что кастомные картинки оно кодирует не оч, не думаю, что в таком случае драгган кому-нибудь нужен. Если что, то это стайлган-штука, которая изменяет НЕ фотографии, а значения в латенте стайлгана, т.е. сгенерированные стайлганом картинки