Time is urgent, hope to solve it soon, thank you!
text is :
ホ<u=200B>ッ<u=200B>ツ<u=200B>先<u=200B>生<u=200B>は<u=200B>昔<u=200B>こ<u=200B>こ<u=200B>の<u=200B>名<u=200B>誉<u=200B>市<u=200B>民<u=200B>の<u=200B>称<u=200B>号<u=200B>を<u=200B>取<u=200B>っ<u=200B>た<u=200B>こ<u=200B>と<u=200B>も<u=200B>あ<u=200B>っ<u=200B>た<u=200B>ん<u=200B>だ<u=200B>っ<u=200B>た<u=200B>な…<u=200B>え<u=200B>ー<u=200B>と、<u=200B>あ<u=200B>れ<u=200B>は<u=200B>何<u=200B>年<u=200B>前<u=200B>の<u=200B>こ<u=200B>と<u=200B>だ<u=200B>っ<u=200B>た<u=200B>か<u=200B>な<u=200B>?<u=200B>覚<u=200B>え<u=200B>て<u=200B>は<u=200B>い<u=200B>る<u=200B>ん<u=200B>だ<u=200B>が、<u=200B>具<u=200B>体<u=200B>的<u=200B>な<u=200B>こ<u=200B>と<u=200B>が<u=200B>思<u=200B>い<u=200B>出<u=200B>せ<u=200B>な<u=200B>い…<u=200B>も<u=200B>う<u=200B>年<u=200B>だ<u=200B>な。
inspector : 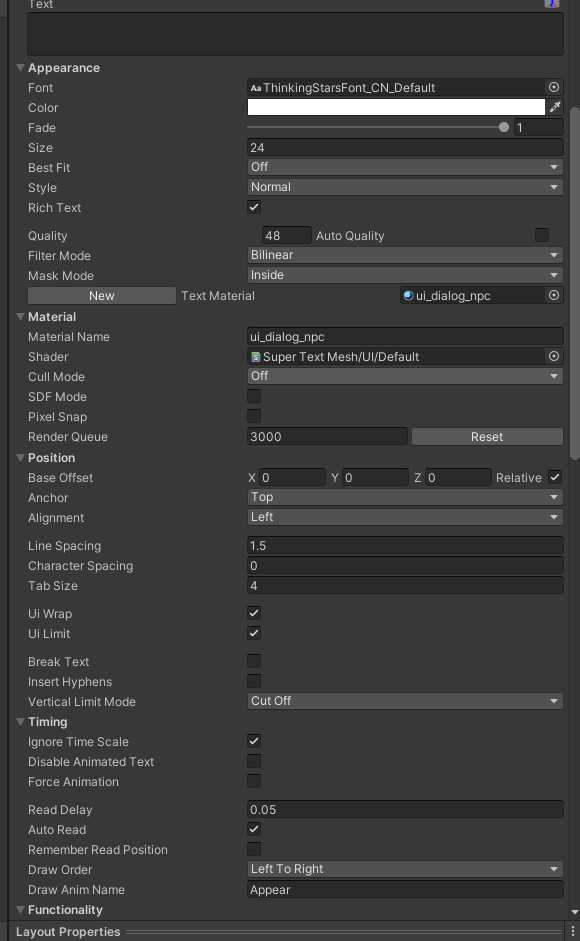
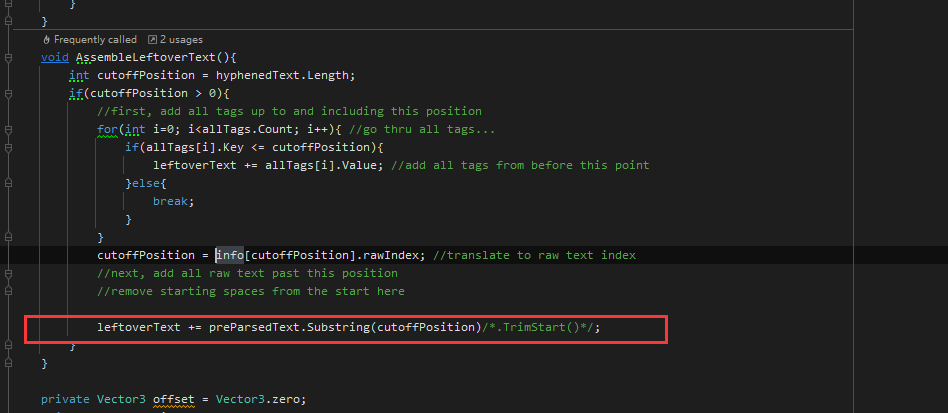
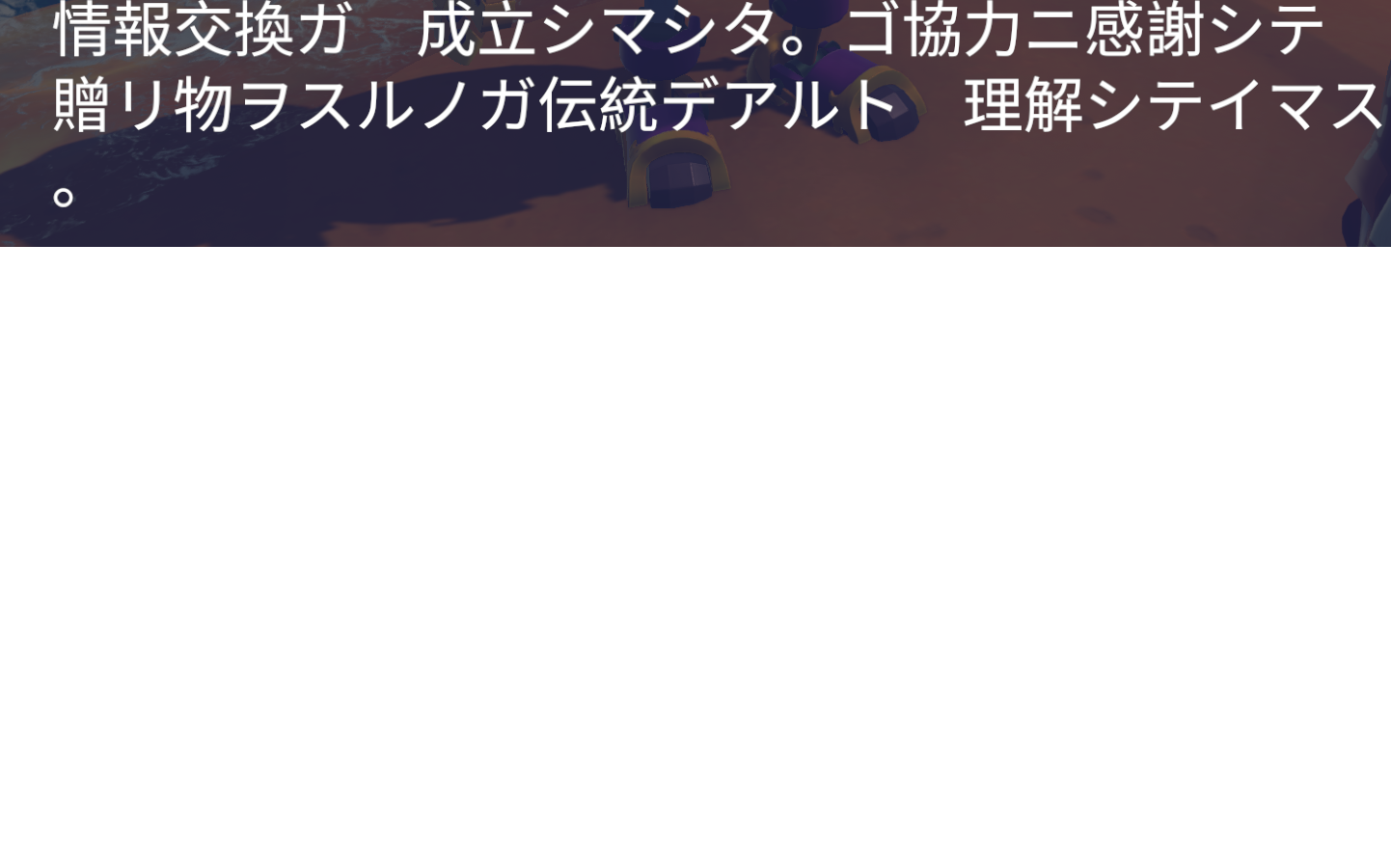
Hi great product. Using it on Critter Cove which is coming out on steam shortly. Having this same issue with our Japanese translator and it appears to now work without issue with ! but not with periods as shown here. So is there something I am doing wrong? See the stranded Japanese . at the end of the sentence.
If its something we need to expand ourselves just point me in the right direction. Basically our biggest issue right now is just grabbing the character previous to the punctuation and putting the line break before that so that we do not start sentences with punctuation as shown here. Interesting that it seems you addressed this but for the life of me I cannot seem to consistently get it to work for some reason.
Hi! Thanks for using STM, it means a ton!
I'm on vacation right now, but I'll give this a quick look...
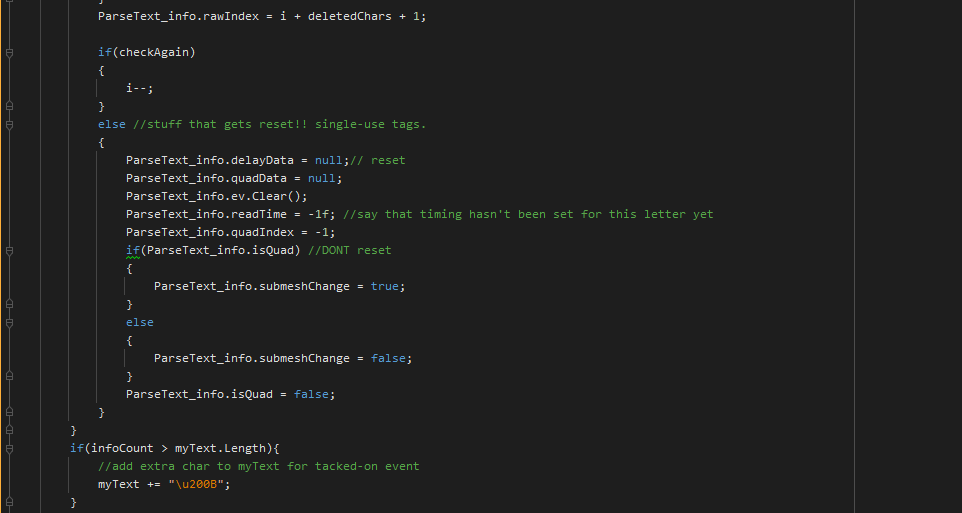
Is the character '。' exactly? In STM, there's a long array of "linebreakUnfriendlyCharacters" which controls what characters can never appear at the start of a line, and this character is in it... Can you make sure there's no space/zero-width space before the '。'?
Also, is the variable "breakText" disabled in the STM inspector? Does disabling "insertHyphens" when using Japanese text make a diff at all?
Off the top of my head, those are two things I can think of to look at first! If neither of those work, I'll have to figure out what it could be... In that case, could you paste that exact string of text you're sending to STM here?
* OK FOR NOW IGNORE THIS. Appears the update did not take last time and so now I see the changes. Sorry about that stupid unity said it was on the latest version but some of the files apparently did not take. Fixing and will let you know if there are any issues.
WORKING AS DESIGNED NOW. Again sorry.
Here is the exact text. You can see there is no space at all at the end character '。' Actual text is included at the bottom.
Toggling off and on the hyphen made no difference. Thanks for the help going to take a look as well inside the code.
Also using a true type font so not sure if that has something to do with it??? Though it does appear to be working sometimes with ! inside of text ie not at the end.
Oh another oddity "linebreakUnfriendlyCharacters" could not find this while searching the code. But I can find linebreakFriendlyChars so that seems odd. Going to check if the update did not take at some point or if my custom changes interfered with that.
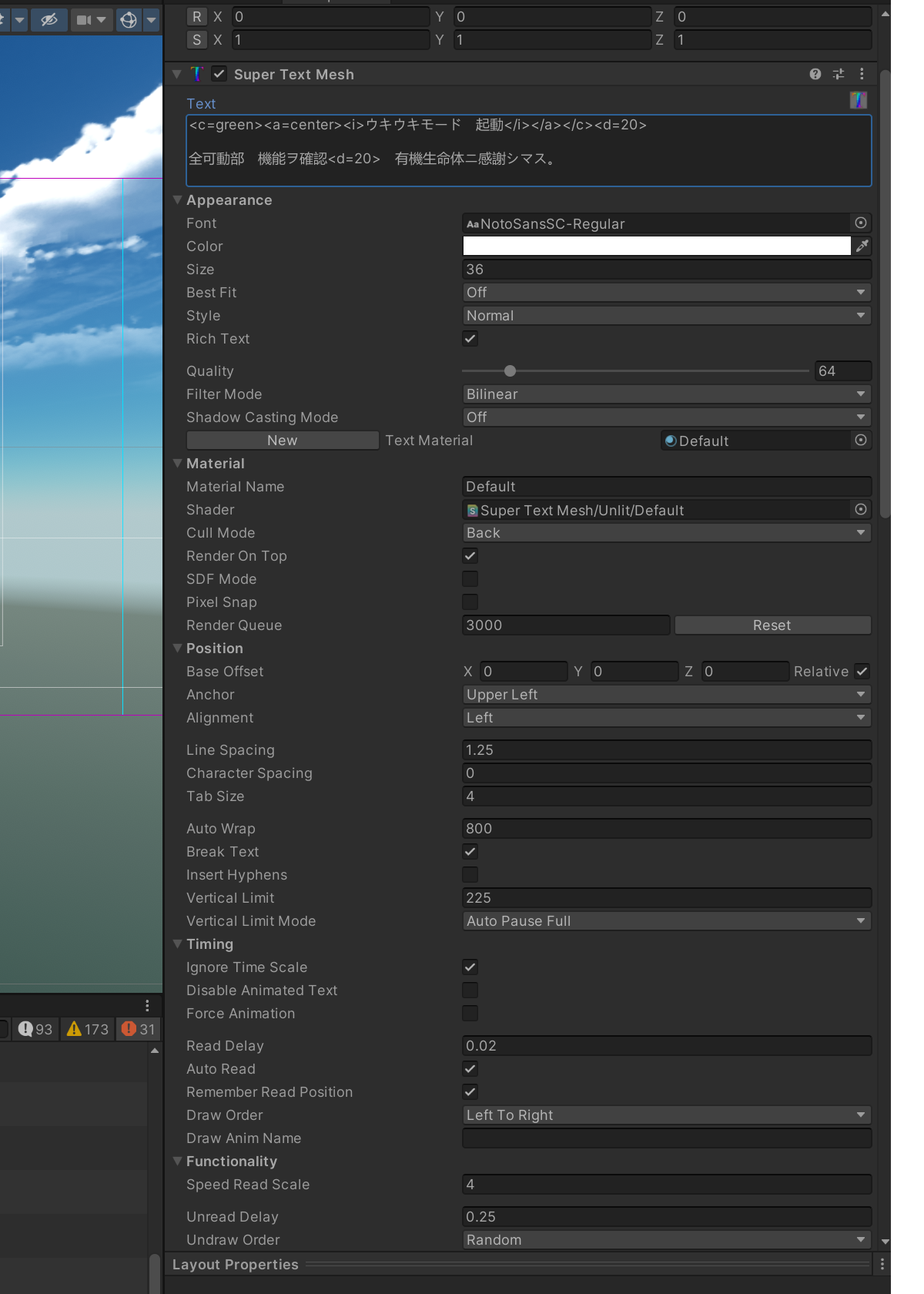
<c=green><a=center><i>ウキウキモード 起動</i></a></c><d=20>
全可動部 機能ヲ確認<d=20> 有機生命体ニ感謝シマス。
It's ok! It's strange, I've actually gotten a few errors where the solution was an update improperly applying... I've even run into it myself when re-importing despite seeing new files and making sure they were checked (in fact, I'm pretty sure that thanks to this, some code in another asset of mine hasn't gotten published so I'm planning a complete manual code comparison...) so... I'm not too sure why Unity's doing that, maybe something could be wrong with my metadata...?
Either way, glad it works!