

Disable your antivirus then. It really shouldn't be flagging it though.
A member registered Sep 07, 2024 · View creator page →
Creator of
Recent community posts
Go into Silverpine_Data\StreamingAssets and open a command prompt there.
Then do: koboldcpp.exe --model "model.gguf" --usecublas --gpulayers 17 --quiet --multiuser 100 --skiplauncher --highpriority
Replace --usecublas with --usevulkan if you have an AMD GPU.
Replace 17 with 27 if you have 8 gb of vram, or 43 if you have 10 gb or more.
This will make it show the full error without closing.
You could try moving the entire game folder to a users folder like downloads so it doesn't need any special permissions, though I don't think that's the problem since it looks like it's creating an access violation trying to read from a 64 bit memory adress.
I can't say anything about this beyond that since searching for this problem doesn't really return anything of substance, and KoboldCPP is third-party software which I didn't develop.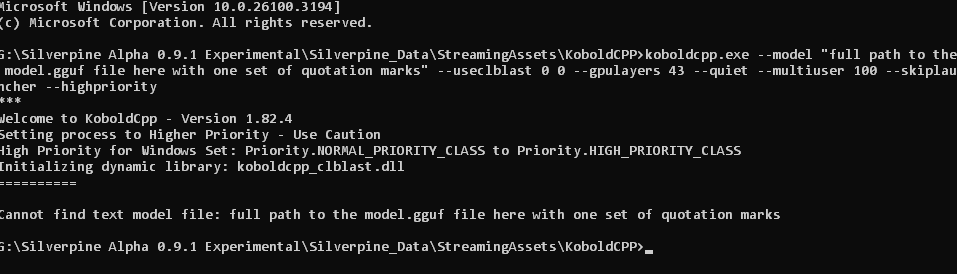
"full path to the model.gguf file here with one set of quotation marks" should be replaced with "G:\Silverpine Alpha 0.9.1 Experimental\Silverpine_Data\StreamingAssets\KoboldCPP\model.gguf" here, assuming you didn't move the folder.
I've added a build that uses a more recent version of KoboldCPP. It might fix the issue.
If it doesn't fix it, open a command prompt inside the KoboldCPP folder like on the screenshot
Then run:
--model "full path to the model.gguf file here with one set of quotation marks" --usevulkan --gpulayers 43 --quiet --multiuser 100 --skiplauncher --highpriority
Which will show you the full error instead of closing the window when the exception happens.
Since windows doesn't seem to provide a way to capture the output of processes without redirecting it and hiding the command prompt completely, the game can't display the actual error by itself.
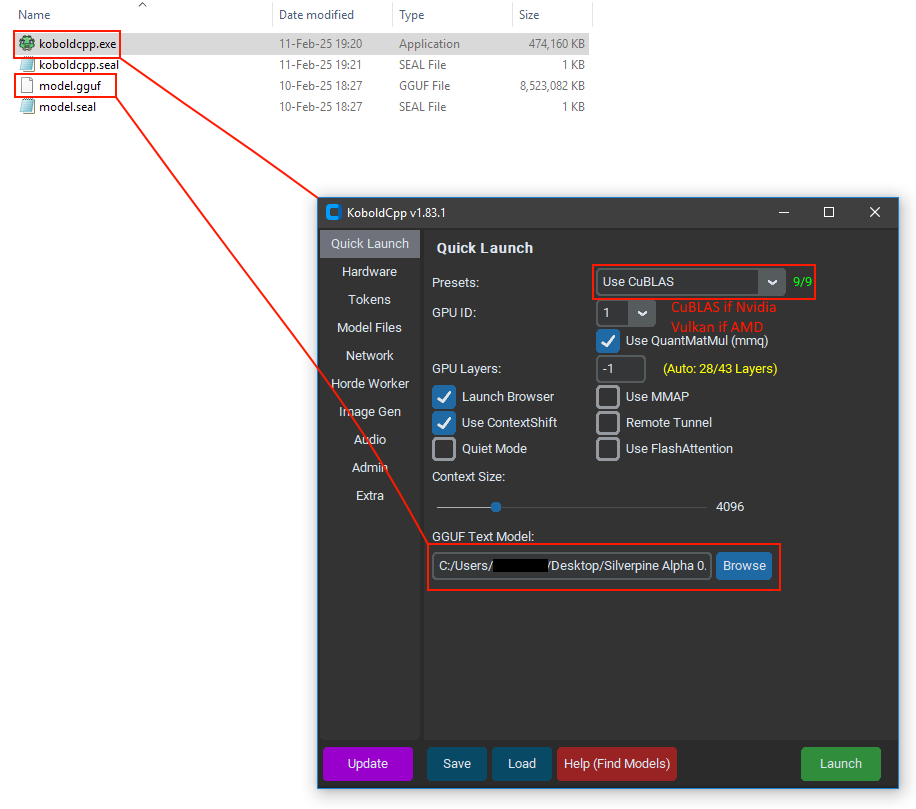
Try replacing the koboldcpp.exe file in Silverpine_Data\StreamingAssets\KoboldCPP with this new version https://github.com/LostRuins/koboldcpp/releases/download/v1.83.1/koboldcpp.exe.
Replace the 467832398 inside koboldcpp.seal (just open it with a text editor) with 485539629 or the game will think koboldcpp.exe has been corrupted.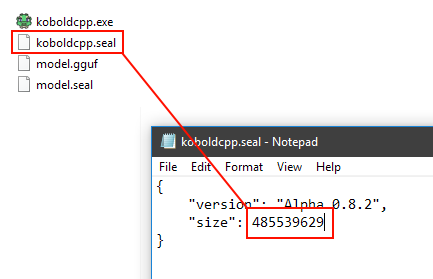
I'm not sure what could be the issue if it just sits there instead of crashing.