

Thanks for the heads up, I've updated the code and releases with additional variables to control the winding order of the faces as well as the culling mode.
A member registered 75 days ago · View creator page →
Creator of
Recent community posts
I appreciate the feedback!
I implemented some additional variables to control the winding order of the faces as well as the culling mode. I think these images should illustrate the fixes:

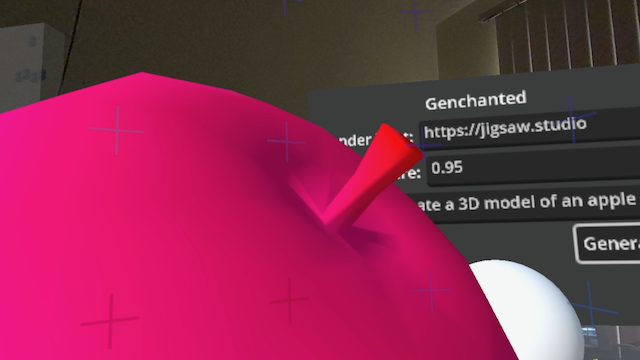
Hosting via WebXR is a little tricky if one domain hosts the game environment (say itch.io) and another is meant to be providing the rendering. I might just need to play more with CORS and other settings next time (where available).
Regards speed I was able to get a hold of a 3090 (24 GB of VRAM) instead of a 3060 (12 GB VRAM) for the remainder of the game jam which makes a massive difference (safetensors model is 16 GB, anything less and processing spills over to system RAM and becomes CPU bound).
Long term I intend to roll the work over into another Open Source project so will keep expanding and improving as better models become available (generating 3D objects is still pretty new).