




Play tool
Genchanted's itch.io pageResults
| Criteria | Rank | Score* | Raw Score |
| Originality - How original was the entry. | #23 | 2.814 | 3.111 |
| User experience - How well was the user interaction implemented. | #26 | 1.608 | 1.778 |
| Theme incorporation - How well did the entry fit the theme. | #26 | 2.211 | 2.444 |
| Haptics - Did the entry make good use of haptics? | #27 | 1.106 | 1.222 |
| Fun factor - How much fun was the entry to play. | #27 | 1.608 | 1.778 |
| Audio - Did the entry make good use of audio? | #27 | 1.106 | 1.222 |
| Overall | #27 | 1.742 | 1.926 |
Ranked from 9 ratings. Score is adjusted from raw score by the median number of ratings per game in the jam.
Godot version used
4.3
Leave a comment
Log in with itch.io to leave a comment.
Comments
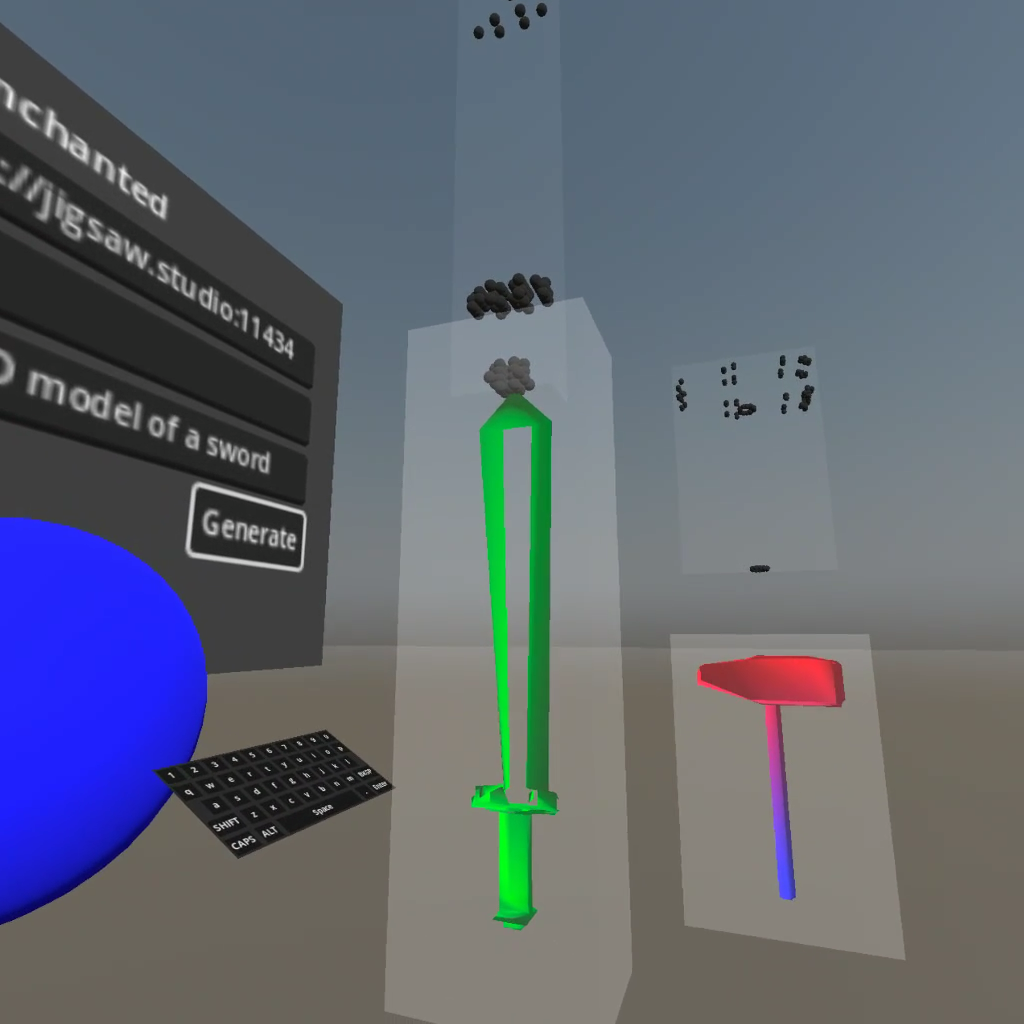
A very interesting experiment on generative 3D meshes. If you have control over the material you may want to disable culling as it looks like the normals are reversed.
Thanks for the heads up, I've updated the code and releases with additional variables to control the winding order of the faces as well as the culling mode.
Kudos on trying to make something challenging. Thanks for setting up the server - I appreciate the extra work and time that takes! Here's the dog it generated :)
Ha ha, (w) oof.
While the training set for the model has not been released, my understanding is they started with the Objaverse dataset, converted GLBs to vector and face object strings (the same thing the model generates as output and we convert back to display), and then filtered out any objects with more than 500 faces. Whatever was left they used for training their model. Therefore any complex objects wouldn't make it in, only simple ones.
I'm still experimenting to discover what remains, because so long as you stick within the training data you'll usually get decent results, anything outside looks like it... kinda melted in the oven.
Ha ha, I also had the same idea! But I feared an online Gen AI server would cost me a lot. I think it would be better to make a set of prebuilt meshes. Not letting the user to type on the keyboard but choosing what to generate, can be faster and cheaper.
The hope is that someone who has PCVR or a Apple Silicon system with enough VRAM (or at least RAM) might be able to host the model entirely themselves, and not have to pay for a service. (Apple Silicon shares CPU RAM with the GPU so while it won't run nearly as fast as NVIDIA hardware it is better than relying on only the CPU.)
The current `llama-mesh` model isn't ideal in size (~16 GB) and may lack enough variety of training data for the long term, but it does work now, and it should be possible to swap out for other models as they come along without too much extra work. Specifically the Ollama quantizations don't produce as reliable results as the original safetensors now, but it would be a single Ollama command to swap out for a new model later, without change to Genchanted's code since it already supports the API.
Very interesting concept! I would love to have the holodeck :-)
Unfortunately, I wasn't able to get it working. I installed and ran Ollama as described in the README, using a port I usually use for testing multiplayer stuff, so I know my headset can reach it. But once I entered all the info, including a new prompt, and clicked "Generate" - nothing happened! I was using the APK on a Meta Quest 3.
I don't know much about Ollama (this is my first time using it), but it does print a log to this console, and it didn't print anything new when I attempted to generate within the app. I don't know if it should say anything about receiving a request and successfully responding, but it certainly didn't print out any errors.
It would be useful if the app itself could show some kind of error message that would help debug problems.
Thanks for checking out the project and the helpful feedback!
I just set up a temporary host running the original `llama-mesh` model under `generate-glb` (a separate Open Source project I wrote last week to help support this Game Jam). There's another post with details (and some caveats).
Regards the UI, yes I need (and intend) to make some tweaks to better show connection and activity, especially as it may take a couple minutes for the preview of the vectors and faces of the model to start appearing, depending on whether or not hardware acceleration is available on the server doing the rendering. I honestly didn't have much time to devote to the UI since most of the week was dedicated to getting generation dialed in (long story short the quantized models used with Ollama don't produce nearly as good results as the original model, but Ollama is the easiest to set up). Meanwhile the easiest way to check if Ollama is doing its thing is if your GPU usage (or at least CPU) starts to spike after clicking "Generate" - not ideal I know!
I will post a follow-up after cleaning up the UI, either late tonight or tomorrow most likely.
I've made some minor enhancements and posted details in the Devlog. I will continue posting update details through the rest of the Game Jam and in the future.
Thanks to a rather handy WebXR tutorial, I've added WebXR support alongside the temporary render host. I'll keep things running for the rest of the weekend for anyone who wants to try out Genchanted without any location installation required:
https://jigsaw.studio/genchanted/
Thanks! I was able to get it working with the WebXR version, and it even ran fairly quickly, at least compared to my expectations after you explained that it is really slow.
The best object I got was this very cube-ular apple:
Very cool! We are on our way to the holodeck :-)
I also tried asking for a house and a heart, and neither of those actually looked like the requested objects.
And all the objects it made seem to have their normals flipped and/or their vertices wound backwards, such that I see the inside faces of objects and the outside faces are culled. I don't know how much control you have over that, but perhaps you need to invert the normals and/or reverse the winding order of what the generator gives you?
Anyway, I hope you keep iterating on this! I'd love to see a more developed version. And, I know it probably isn't easy/cheap to host the server, having it as a WebXR experience really makes it more accessible than with all the setup.
I appreciate the feedback!
I implemented some additional variables to control the winding order of the faces as well as the culling mode. I think these images should illustrate the fixes:
Hosting via WebXR is a little tricky if one domain hosts the game environment (say itch.io) and another is meant to be providing the rendering. I might just need to play more with CORS and other settings next time (where available).
Regards speed I was able to get a hold of a 3090 (24 GB of VRAM) instead of a 3060 (12 GB VRAM) for the remainder of the game jam which makes a massive difference (safetensors model is 16 GB, anything less and processing spills over to system RAM and becomes CPU bound).
Long term I intend to roll the work over into another Open Source project so will keep expanding and improving as better models become available (generating 3D objects is still pretty new).
Would someone be able to spin up a server for the duration of this jam voting period? It's quite a mission getting the ollama thing installed and running
Thanks for checking out the project. I've created a new set of releases (which include "gamejam" in the filename. These point to an internet host, which through a series of SSH tunnels and Docker containers arrives at temporary server running `generate-glb` (a separate Open Source project I wrote last week to help support this Game Jam). This host is running the origin non-quantized `llama-mesh` model, which I've found has better results than Ollama.
There are a few caveats however:
As mentioned above, I've made some minor enhancements and posted details in the Devlog. I will continue posting update details through the rest of the Game Jam and in the future (so there's just one location going forward).
Meanwhile Ihave a better temporary server set up which can load the full model into VRAM, so execution speed should be more reasonable.