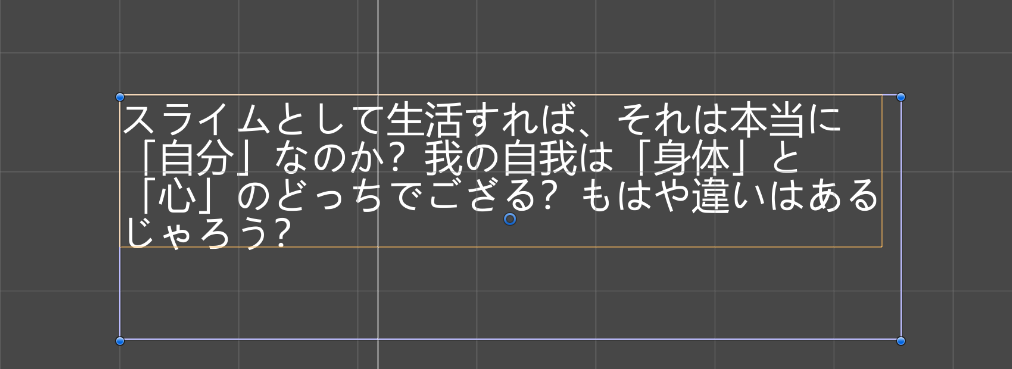
Hey, just encountered an obscure problem involving word wrap (1.13.2). If the final character of a line is a hyphen, it looks like the wrapping doesn't occur until afterward. This seems to happen regardless of whether Insert Hyphens is enabled. This causes the text to expand outside of the RectTransform's bounds, which probably isn't intended behavior (and it can be a problem if the STM is inside a mask, which is what happened to me just now).
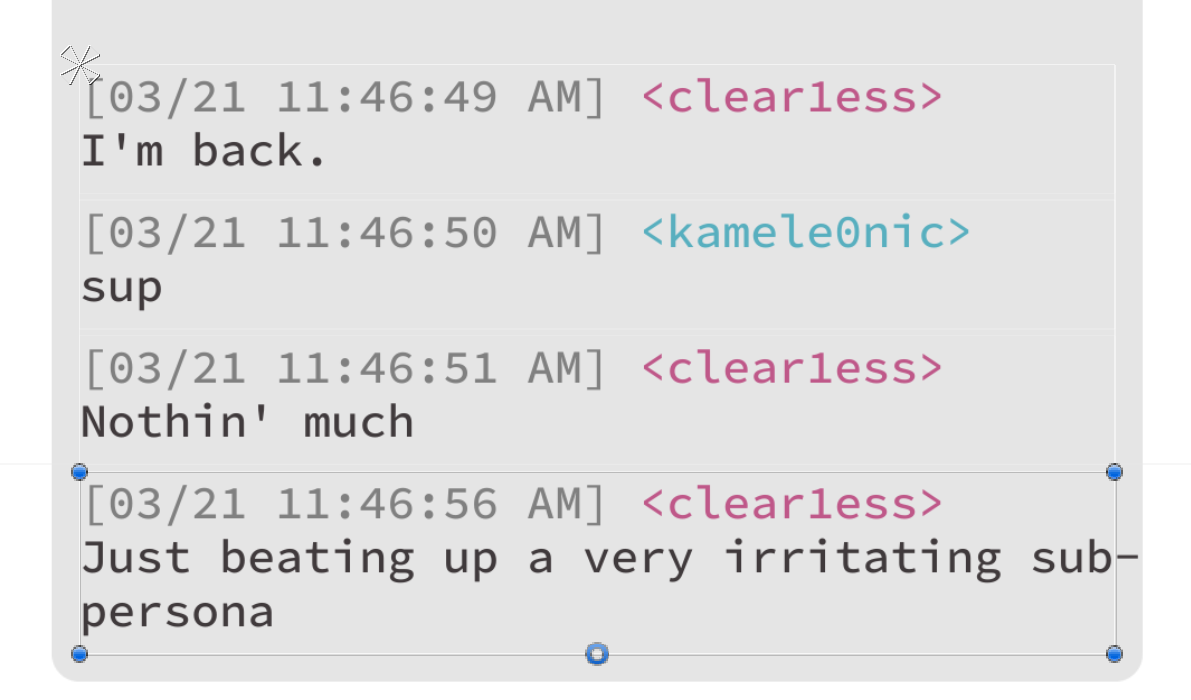
I was able to reproduce this quickly in a blank project, so I think you'll be able to do the same, but let me know if it looks different on your end.